Filter by type:
Filter by tags:

minicpm5-1b-claude-opus-fable5-thinking
# MiniCPM5-1B-Claude-Opus-Fable5-Thinking
GGUF quantizations for local deployment: **MiniCPM5-1B-Claude-Opus-Fable5-Thinking-GGUF**
中文说明
**MiniCPM5-1B-Claude-Opus-Fable5-Thinking** is a compact 1B **Thinking** language model built on openbmb/MiniCPM5-1B. It is further fine-tuned on **Fable 5** data to improve **coding** and **instruction-following** while keeping MiniCPM5's native Thinking chat template and tool-call format.
For llama.cpp / Ollama / LM Studio deployment, see the **GGUF repository**.
## Overview
## Capabilities
- **Coding** — code generation, debugging, and software-engineering-style tasks
- **Instruction following** — more reliable adherence to user prompts and structured constraints
- **Thinking mode** — chain-of-thought reasoning via the MiniCPM5 chat template
- **Tool calling** — inherits MiniCPM5's XML tool-call format
- **Long context** — up to **128K tokens** (131,072 tokens per `config.json`)
## Quick start
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "GnLOLot/MiniCPM5-1B-Claude-Opus-Fable5-Thinking"
...
Repository: localaiLicense: apache-2.0
deepseek-v4-flash
# DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
Technical Report👁️
## Introduction
We present a preview version of **DeepSeek-V4** series, including two strong Mixture-of-Experts (MoE) language models — **DeepSeek-V4-Pro** with 1.6T parameters (49B activated) and **DeepSeek-V4-Flash** with 284B parameters (13B activated) — both supporting a context length of **one million tokens**.
DeepSeek-V4 series incorporate several key upgrades in architecture and optimization:
1. **Hybrid Attention Architecture:** We design a hybrid attention mechanism combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to dramatically improve long-context efficiency. In the 1M-token context setting, DeepSeek-V4-Pro requires only **27% of single-token inference FLOPs** and **10% of KV cache** compared with DeepSeek-V3.2.
2. **Manifold-Constrained Hyper-Connections (mHC):** We incorporate mHC to strengthen conventional residual connections, enhancing stability of signal propagation across layers while preserving model expressivity.
3. **Muon Optimizer:** We employ the Muon optimizer for faster convergence and greater training stability.
...
Repository: localaiLicense: mit

qwopus3.6-35b-a3b-coder-mtp
# 🌟 Qwopus3.6-35B-A3B-v1
## 💡 Base Model Overview
**Qwen3.6-35B-A3B** is an advanced hybrid sparse MoE (Mixture-of-Experts) model developed by Alibaba Cloud. It features 35B total parameters with only 3B active parameters per token, ensuring high inference efficiency. Architecturally, it combines Gated DeltaNet linear attention with standard gated attention layers, routing tokens across **256 experts**. It natively supports a massive **262k context window** and is specifically designed for high-performance agentic coding, deep reasoning, and multimodal tasks.
## 🚀 Model Refinement & Logic Tuning (Qwopus3.6-35B-A3B-v1)
🪐**Qwopus3.6-35B-A3B-v1** is a reasoning-enhanced MoE (Mixture of Experts) model fine-tuned on top of **Qwen3.6-35B-A3B**.
### 🛠 Training Strategy
The fine-tuning process for this model is structured into **three distinct stages of distributed SFT (Supervised Fine-Tuning)**, progressively scaling reasoning complexity and data diversity. This systematic approach ensures the model inherits the base MoE capabilities while sharpening its logic-handling depth.
...
Repository: localaiLicense: apache-2.0
ornith-1.0-9b-mtp
[](https://deep-reinforce.com/ornith.html)
# Ornith-1.0-9B
Aloha! 🌺 Today, we are releasing Ornith-1.0, a self-improving family of open-source models for agentic coding.
Highlights:
- **State-of-the-Art Coding Agents**: Available in 9B-Dense, 31B-Dense, 35B-MoE, and 397B-MoE (post-trained on top of Gemma 4 and Qwen 3.5), achieving state-of-the-art performance among open-source models of comparable size on coding benchmarks such as Terminal-Bench 2.1, SWE-Bench, NL2Repo and OpenClaw.
- **Self-Improving Training Framework**: Ornith-1.0 employs RL to learn to generate not only solution rollouts, but also the scallfold that drive those rollouts. By jointly optimizing the scaffold and the resulting solution, the model discovers better search trajectories and generates higher-quality solutions.
- **Licence**: MIT licensed, globally accessible, and free from regional limitations.
## Ornith 1.0 9B
This model card documents **Ornith-1.0-9B**, the most lightweight member of the Ornith family, designed for efficient single-GPU deployment.
### Benchmarks
Ornith-1.0-9B
Qwen3.5-9B
Qwen3.5-35B
Gemma4-12B
Gemma4-31B
Agentic Coding
...
Repository: localaiLicense: mit
qwen-agentworld-35b-a3b
# Qwen-AgentWorld-35B-A3B
📑 Technical Report |
📖 Blog |
🤗 Hugging Face |
🤖 ModelScope |
💻 GitHub |
🖥️ Demo
> [!Note]
> This repository contains the model weights and configuration files for **Qwen-AgentWorld-35B-A3B**, a native language world model trained for agentic environment simulation.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, etc.
**Qwen-AgentWorld** is the first language world model to cover seven agent interaction domains within a single model. It simulates agentic environments via long chain-of-thought reasoning, predicting the next environment state given an agent's action and interaction history. Trained through a three-stage pipeline — CPT injects environment knowledge, SFT activates next-state-prediction reasoning, RL sharpens simulation fidelity — Qwen-AgentWorld is a **native world model**: environment modeling is the training objective from the CPT stage onward, not a post-hoc add-on.
## Highlights
...
Repository: localaiLicense: apache-2.0
ornith-1.0-9b
[](https://deep-reinforce.com/ornith.html)
# Ornith-1.0-9B-GGUF
Aloha! 🌺 Today, we are releasing Ornith-1.0, a self-improving family of open-source models for agentic coding.
Highlights:
- **State-of-the-Art Coding Agents**: Available in 9B-Dense, 31B-Dense, 35B-MoE, and 397B-MoE (post-trained on top of Gemma 4 and Qwen 3.5), achieving state-of-the-art performance among open-source models of comparable size on coding benchmarks such as Terminal-Bench 2.1, SWE-Bench, NL2Repo and OpenClaw.
- **Self-Improving Training Framework**: Ornith-1.0 employs RL to learn to generate not only solution rollouts, but also the scallfold that drive those rollouts. By jointly optimizing the scaffold and the resulting solution, the model discovers better search trajectories and generates higher-quality solutions.
- **Licence**: MIT licensed, globally accessible, and free from regional limitations.
## Ornith 1.0 9B
This model card documents **Ornith-1.0-9B**, the most lightweight member of the Ornith family, designed for efficient single-GPU deployment.
### Benchmarks
Ornith-1.0-9B
Qwen3.5-9B
Qwen3.5-35B
Gemma4-12B
Gemma4-31B
Agentic Coding
...
Repository: localaiLicense: mit
ornith-1.0-35b
[](https://deep-reinforce.com/ornith.html)
# Ornith-1.0-35B-GGUF
Aloha! 🌺 Today, we are releasing Ornith-1.0, a self-improving family of open-source models for agentic coding.
Highlights:
- **State-of-the-Art Coding Agents**: Available in 9B-Dense, 31B-Dense, 35B-MoE, and 397B-MoE (post-trained on top of Gemma 4 and Qwen 3.5), achieving state-of-the-art performance among open-source models of comparable size on coding benchmarks such as Terminal-Bench 2.1, SWE-Bench, NL2Repo and OpenClaw.
- **Self-Improving Training Framework**: Ornith-1.0 employs RL to learn to generate not only solution rollouts, but also the scallfold that drive those rollouts. By jointly optimizing the scaffold and the resulting solution, the model discovers better search trajectories and generates higher-quality solutions.
- **Licence**: MIT licensed, globally accessible, and free from regional limitations.
## Ornith 1.0 35B
This model card documents **Ornith-1.0-35B**, the lightweight member of the Ornith family, designed for efficient single-GPU deployment.
### Benchmarks
Ornith-1.0-35B
Qwen3.5-35B
Qwen3.6-35B
Gemma4-31B
Qwen3.5-397B
Agentic Coding
...
Repository: localaiLicense: mit

gemmable-4-12b-mtp
## Gemmable 4 12B
Gemmable 4 12B is a GGUF export of Gemma 4 12B fine-tuned on Fable-5 style
reasoning and assistant traces.
## Highlights
- Base model: `google/gemma-4-12B`
- Format: GGUF
- Training style: Fable-5 style reasoning and assistant traces
- Distribution: fp16 GGUF plus matching assistant GGUFs for each quant
- Intended use: local inference, coding, reasoning, and assistant workflows
## How to use
### llama.cpp
Standard load:
```bash
llama-server -m "gemmable-4-12b-fp16.gguf"
```
Speculative / draft-MTP load:
```bash
llama-server -m "gemmable-4-12b-Q4_K_M.gguf" \
--spec-draft-model "gemmable-4-12b-Q4_K_M-mtp.gguf" \
--spec-type draft-mtp \
--spec-draft-n-max 4
```
Use the matching fp16 or quantized main file with its `-mtp` companion.
### LM Studio
1. Search this repo, download target + mtp file.
2. Load target.
3. Load settings → Speculative Decoding → select mtp file file.
(Requires LM Studio with am17an's PR merged or custom llama.cpp runtime. As of 2026-05, mainline LM Studio runtime doesn't yet have `draft-mtp` for Gemma-4 — track upstream merge.)
## GGUF / local inference notes
...
Repository: localai

lfm2.5-1.2b-instruct
Try LFM • Docs • LEAP • Discord
# LFM2.5-1.2B-Instruct
LFM2.5 is a new family of hybrid models designed for **on-device deployment**. It builds on the LFM2 architecture with extended pre-training and reinforcement learning.
- **Best-in-class performance**: A 1.2B model rivaling much larger models, bringing high-quality AI to your pocket.
- **Fast edge inference**: 239 tok/s decode on AMD CPU, 82 tok/s on mobile NPU. Runs under 1GB of memory with day-one support for llama.cpp, MLX, and vLLM.
- **Scaled training**: Extended pre-training from 10T to 28T tokens and large-scale multi-stage reinforcement learning.
Find more information about LFM2.5 in our blog post.
## 🗒️ Model Details
LFM2.5-1.2B-Instruct is a general-purpose text-only model with the following features:
...
Repository: localaiLicense: other

qwopus3.6-27b-coder-compat-mtp
🪐 Qwopus-3.6-27B-Coder
Coder SFT Release
Agentic Coding & Tool-Use Reasoning Model Fine-Tuned on Qwopus3.6-27B-v2
🧬 Trace Inversion & Negentropy
🧠 27B Dense Model
⚡ Agentic Coding
🛠️ Tool Calling & Agent
🏆 SWE-bench Verified: 67.0% (off-thinking)
💡 What is Qwopus-3.6-27B-Coder?
🪐 Qwopus-3.6-27B-Coder is a reasoning-enhanced agentic coding model built on top of Qwopus3.6-27B-v2. It inherits the powerful reasoning foundation of the v2 base — which achieved 87.43% MMLU-Pro and 75.25% SWE-bench Verified — and further specializes it for agentic code generation, structured tool calling, debugging, and instruction-following in developer workflows. The model is designed to excel at repository-level coding tasks, multi-turn tool orchestration, and complex logical reasoning under realistic agent environments.
🧩 Agentic Coding
Optimized for repository-level coding, debugging, patch generation, and structured multi-step development workflows.
🛠️ Tool Calling
Learns from real agent trajectories with tool definitions, tool calls, and environment feedback for robust multi-turn execution.
...
Repository: localaiLicense: apache-2.0
kimi-k2.7-code
## 1. Model Introduction
Kimi K2.7 Code is a coding-focused agentic model built upon Kimi K2.6. With substantial improvements on real-world long-horizon coding tasks, it strengthens end-to-end task completion across complex software engineering workflows while improving token efficiency, reducing thinking-token usage by approximately 30% compared with Kimi K2.6.
## 2. Model Summary
## 3. Evaluation Results
Benchmark
Kimi K2.6
Kimi K2.7 Code
GPT-5.5
Claude Opus 4.8
Coding
Kimi Code Bench v2
50.9
62.0
69.0
67.4
Program Bench
48.3
53.6
69.1
63.8
MLS Bench Lite
26.7
35.1
35.5
42.8
Agentic
Kimi Claw 24/7 Bench
42.9
46.9
52.8
50.4
MCP Atlas
69.4
76.0
79.4
81.3
MCP Mark Verified
72.8
81.1
92.9
76.4
Footnotes
...
Repository: localaiLicense: other
qwythos-9b-claude-mythos-5-1m
# Qwythos-9B
**Developed by Empero**
**Qwythos-9B** is a full-parameter reasoning model built on top of a **deeply uncensored Qwen3.5-9B base** and post-trained on **over 500 million tokens** of high-quality Claude Mythos and Claude Fable traces, with chain-of-thought generated in-house by Empero AI's internal tool **rethink**.
The result is a compact, fast, **dramatically more capable** 9B reasoning model. Headline capabilities:
...
Repository: localaiLicense: apache-2.0
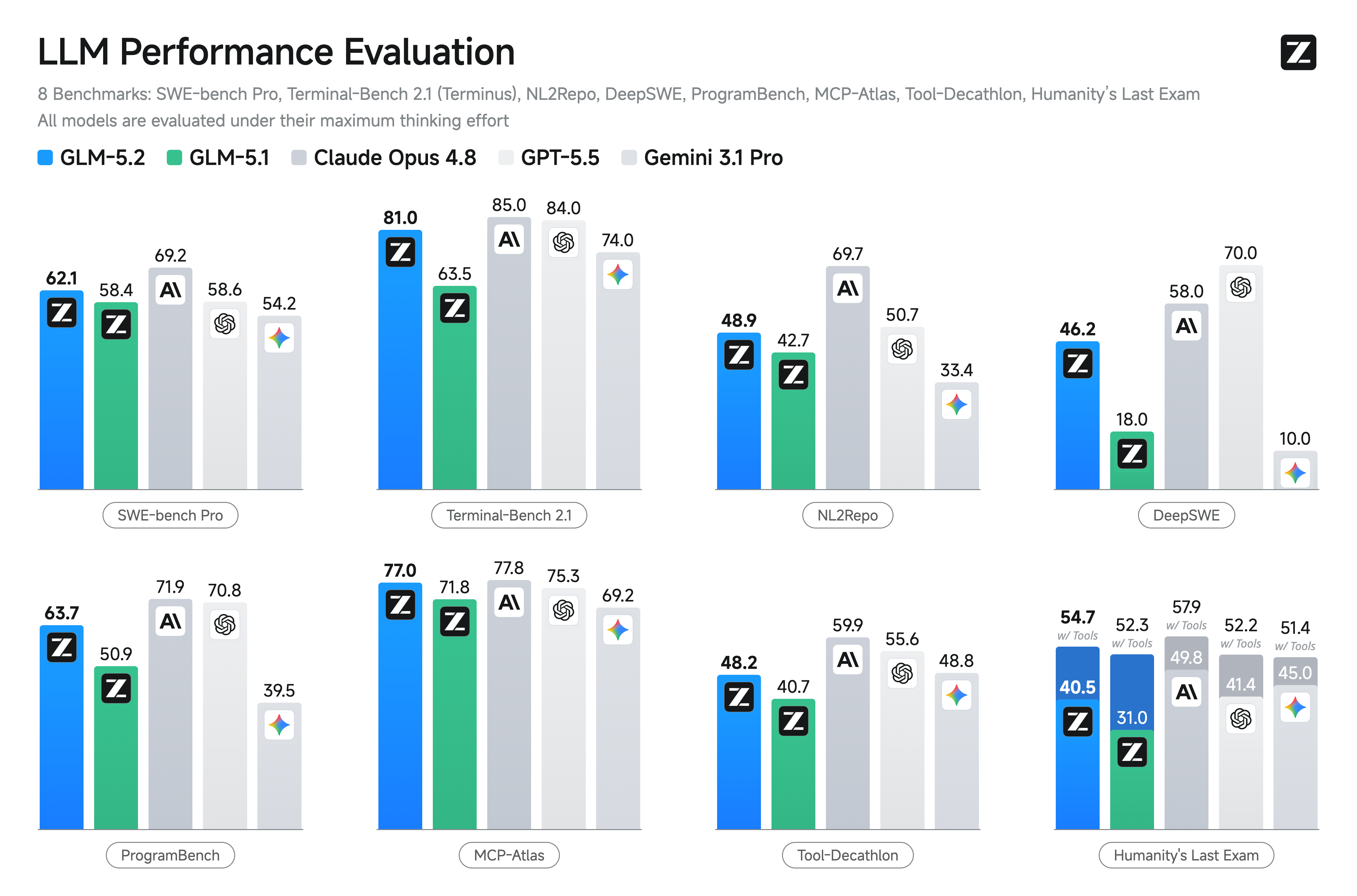
glm-5.2
# GLM-5.2
👋 Join our WeChat or Discord community.
📖 Check out the GLM-5.2 blog and GLM-5 Technical report.
📍 Use GLM-5.2 API services on Z.ai API Platform.
🔜 Try GLM-5.2 here.
[Paper]
[GitHub]
## Introduction
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a **solid 1M-token context**. GLM-5.2's new capabilities include:
- **Solid 1M Context:** A solid 1M-token context that stably sustains long-horizon work
- **Advanced Coding with Flexible Effort**: Stronger coding capabilities with multiple thinking effort levels to balance performance and latency
- **Improved Architecture**: We propose IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. We also improve GLM-5.2’s MTP layer for speculative decoding, increasing the acceptance length by up to 20%
- **Pure Open**: An MIT open-source license — no regional limits, technical access without borders
## Benchmark
## Serve GLM-5.2 Locally
...
Repository: localaiLicense: mit

qwen3.6-35b-a3b-nvfp4-mtp
# Qwen3.6-35B-A3B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-35B-A3B.
## Model Overview
...
Repository: localai
qwopus3.6-27b-v2-mtp-nvfp4
🪐 Qwopus3.6-27B-v2-MTP
MTP Release
Multi-Token Prediction reasoning model fine-tuned from Qwen3.6-27B
🧬 Trace Inversion & Negentropy
🧠 27B Parameters
⚡ Speculative Decoding
🛠️ Coding / DevOps / Math
💡 What is Qwopus3.6-27B-v2-MTP?
🪐 Qwopus3.6-27B-v2-MTP is a speed-oriented reasoning release built on top of Qwen3.6-27B. It keeps the Qwopus line's focus on reconstructed reasoning traces, coding discipline, DevOps procedures, and mathematical derivations, while adding Multi-Token Prediction for faster generation. The goal is simple: preserve the depth and structure of a 27B reasoning model while making real interactive use noticeably faster.
⚡ MTP DecodingAuxiliary future-token prediction improves throughput on long reasoning, code, math, and strict-format prompts.
🧩 Structured ReasoningInherits the Qwopus training recipe built around reconstructed step-by-step reasoning trajectories.
🧪 GB10 TestedValidated on a 30-question local benchmark across Logic, Coding, DevOps, Math, and Edge tasks.
🚀 Practical SpeedDesigned for workflows where strong answers matter, but waiting several extra minutes per task does not.
...
Repository: localai
qwopus3.6-27b-coder-mtp-nvfp4
🪐 Qwopus-3.6-27B-Coder
Coder SFT Release
Agentic Coding & Tool-Use Reasoning Model Fine-Tuned on Qwopus3.6-27B-v2
🧬 Trace Inversion & Negentropy
🧠 27B Dense Model
⚡ Agentic Coding
🛠️ Tool Calling & Agent
🏆 SWE-bench Verified: 67.0% (off-thinking)
💡 What is Qwopus-3.6-27B-Coder?
🪐 Qwopus-3.6-27B-Coder is a reasoning-enhanced agentic coding model built on top of Qwopus3.6-27B-v2. It inherits the powerful reasoning foundation of the v2 base — which achieved 87.43% MMLU-Pro (300ex) and 75.25% SWE-bench Verified — and further specializes it for agentic code generation, structured tool calling, debugging, and instruction-following in developer workflows. The model is designed to excel at repository-level coding tasks, multi-turn tool orchestration, and complex logical reasoning under realistic agent environments.
🧩 Agentic Coding
Optimized for repository-level coding, debugging, patch generation, and structured multi-step development workflows.
🛠️ Tool Calling
Learns from real agent trajectories with tool definitions, tool calls, and environment feedback for robust multi-turn execution.
...
Repository: localai

qwen3.6-27b-nvfp4-mtp
# Qwen3.6-27B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-27B.
## Model Overview
...
Repository: localai

gemma-4-12b-agentic-fable5-composer2.5-v2-3.5x-tau2
Hugging Face |
GitHub |
Launch Blog |
Documentation
License: Apache 2.0 | Authors: Google DeepMind
> [!Note]
> This model card is for the Gemma 4 12B Unified model, which is part of the Gemma 4 family of open models. Built with the same multimodal functionality as Gemma 4 E2B and E4B (text, audio, image, and video inputs), it brings native audio and vision understanding directly to local environments without the need for separate encoders. This unified approach to multimodality makes the model encoder-free, offering a deployment size that is perfect for consumer devices and streamlined local execution.
Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on E2B, E4B, and 12B) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned variants. Gemma 4 features a context window of up to 256K tokens and maintains multilingual support in over 140 languages.
...
Repository: localaiLicense: apache-2.0
qwen3.6-27b-mtp-pi-tune
# Qwen3.6-27B
[](https://chat.qwen.ai)
> [!Note]
> This repository contains model weights and configuration files for the post-trained model in the Hugging Face Transformers format.
>
> These artifacts are compatible with Hugging Face Transformers, vLLM, SGLang, KTransformers, etc.
Following the February release of the Qwen3.5 series, we're pleased to share the first open-weight variant of Qwen3.6. Built on direct feedback from the community, Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.
## Qwen3.6 Highlights
This release delivers substantial upgrades, particularly in
- **Agentic Coding:** the model now handles frontend workflows and repository-level reasoning with greater fluency and precision.
- **Thinking Preservation:** we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead.
For more details, please refer to our blog post Qwen3.6-27B.
## Model Overview
...
Repository: localaiLicense: apache-2.0
gemma-4-12b-coder-fable5-composer2.5-v1
Hugging Face |
GitHub |
Launch Blog |
Documentation
License: Apache 2.0 | Authors: Google DeepMind
> [!Note]
> This model card is for the Gemma 4 12B Unified model, which is part of the Gemma 4 family of open models. Built with the same multimodal functionality as Gemma 4 E2B and E4B (text, audio, image, and video inputs), it brings native audio and vision understanding directly to local environments without the need for separate encoders. This unified approach to multimodality makes the model encoder-free, offering a deployment size that is perfect for consumer devices and streamlined local execution.
Gemma is a family of open models built by Google DeepMind. Gemma 4 models are multimodal, handling text and image input (with audio supported on E2B, E4B, and 12B) and generating text output. This release includes open-weights models in both pre-trained and instruction-tuned variants. Gemma 4 features a context window of up to 256K tokens and maintains multilingual support in over 140 languages.
...
Repository: localaiLicense: gemma

serenity-26b-a4b
.mc-wrap{background:#0d1117;color:#c9d1d9;font-family:'Inter',sans-serif;max-width:920px;margin:0 auto;padding:24px;border-radius:16px;box-sizing:border-box}
.mc-wrap *{box-sizing:border-box}
.mc-wrap h1,.mc-wrap h2,.mc-wrap h3,.mc-wrap h4{color:#e6edf3;border:none}
.mc-wrap p{color:#c9d1d9}
.mc-wrap strong{color:#7ee8d0}
.mc-wrap a{color:#7ee8d0;text-decoration:none}
.mc-wrap ul{list-style:none;padding-left:0;margin:0}
.mc-wrap li{color:#c9d1d9;margin-bottom:8px;padding-left:4px}
.mc-wrap code{background:#161b22;color:#7ee8d0;padding:2px 8px;border-radius:4px;font-family:'JetBrains Mono',monospace;font-size:.88em;border:1px solid rgba(126,232,208,.15)}
.mc-hdr{text-align:center;padding:40px 32px;background:#0d1117;border:1px solid #21262d;border-radius:24px;margin-bottom:20px;position:relative;overflow:hidden}
.mc-hdr::before{content:'';position:absolute;top:0;left:0;right:0;height:3px;background:linear-gradient(135deg,#7ee8d0,#a78bfa,#c4b5fd)}
.mc-name{font-family:'Space Grotesk',sans-serif;font-size:2.8em;font-weight:800;margin:0;letter-spacing:-.02em;background:linear-gradient(135deg,#7ee8d0,#a78bfa,#c4b5fd);-webkit-background-clip:text;-webkit-text-fill-color:transparent;backg
...
Repository: localaiLicense: apache-2.0
Page 1